- English
- Francais






Reusing LOD Vocabularies: It's not all it's cracked up to be.
posted by warren
on Tue, 03/24/2015 - 12:14

"Re-use data, re-use vocabularies", this has been the battle cry for Linked Open Data and Semantic Web enthusiasts since day one. Formally, the W3C Government Linked Data Working Group has published a Working Group Note on the matter where they state that "Standardized vocabularies should be reused as much as possible to facilitate inclusion and expansion of the Web of data". What seems to be a reasonable point of vue has been pushed a little bit too strongly of late. Bibframe, an effort by the Library of Congress to push beyond MARC, has met a significant amount of criticism for not reusing existing vocabularies instead of rolling its own vocabulary. The BBC also decided to create its own vocabularies that bare a uncanny resemblance to other well known vocabularies instead of building on known ontologies. So what should you do? Is using pre-existing vocabularies really a best practice?
"Which vocabulary to use" triggers arguments that border on the religious, yet few people really understand what the vocabulary implies about the data. For example, the choice between using a geo:Point's and a asWKT("POINT (x y)") 1 entails uncertainties about location and data consistency.
The Linked Open Vocabularies (LOV) website lists over 475 vocabularies while the prefix.cc database lists over 1,508 vocabularies available for re-use. But by Linked Open Data Vocabularies, people mean one of three things:
- Schemas such as the XML Schema define data-types (xsd:int and xsd:dateTime.) and basic structures (like XML). The formal definition is needed but besides serving as a bootstrap for format parsers, the document is mostly useful to lock in a range for a term.
- Vocabularies such as Dublin Core elements, which have neither ranges or domains and are deprecated by Dublin Core Terms, provide an identifier through a url for a piece of information.
- Ontologies, such as Bibo, have a structured, declared format for the data and how it is going to relate to other pieces of data out there. OWL provides a mechanism to import other ontologies into your own for data publications and this is reviewed by some as a means of extending a new vocabulary for a new dataset.
A really nice piece written in 2012 by Phil Archer talks about the completeness of vocabularies, their purposes and tradeoffs about the coverage. I would argue that the 80% use case for a number of properties is to have something to put up on the screen for the user to see. This is one of the reasons that void recommends the use of generic Dublin Core elements within dataset descriptions but provide their own custom property void:inDataset for linking datasets and nodes to their dataset description.
Suggested good practice for the re-use of a vocabulary:
- The vocabulary must be dereferencable, that is available through an http request that matches it's base, in a format that is machine readable. It's better if it is available in multiple linked open data formats (rdf/xml, n3, ttl, etc..). If machines can't read the vocabulary definition, they they can't read your data either.
- The vocabulary has to fit the needs of the data in modeling not only in marking up its contents, but in recording implicit, unwritten assumptions: if your data is about is about facts at a specific point in time, then you should have some way of recording it.
- The vocabulary must have an expectation of being available for as long as the dataset will be made available. In some cases this may mean that you want to re-host the vocabulary on your own server through some creative uses of OWL: if the vocabulary definition goes away, so does people's ability to interpret your data.
- The vocabulary must be relatively stable. If the semantics of the term definition changes, then the meaning of your own data changes also. Picking vocabularies that have machine readable versioning and deprecation tags is a sign that the vocabulary authors care about how their actions affect downstream users.
- The vocabulary has to provide a level of specificity that is appropriate to your dataset. A typical example would be the under-specification of Dublin core: A recording of a song might have the triple <foaf:Document> <dc:subject> "French Song"@en, causing some confusion to a human being, let alone to a machine, as to whether the song is culturally French or interpreted in French.
Consumers of Linked Open Data requires a grounding - Somewhere.
At the end of the day, someone will write a piece of software that will either present the contents of the Linked Open Data to the user on the screen or plug its value into some other piece of code. That requires the programmer writing the software to understand what specific term he is looking for and when/where to look for it. At the very top-level, finding a class or property that might have what you are looking for isn't all that hard: the vocabularies provide <rdfs:comment>, <skos:definition>, <rdfs:label>, etc.. to identify to a human-being what is in the term and that provides you the information you need to create a query to retrieve that information.
The problem that occurs next is a bit of a paradox: You can re-use existing vocabularies but documenting the relationships between those vocabularies is going to require some machine readable OWL/RDF glue which necessitates changing the value of the tag / uri. This should not be a problem since this is all machine readable, yet the great majority of people do not consume Linked Open Data with a reasoner.
Part of the notions about publishing data using existing standards in Linked Open Data is a holdover from the days of XML where the tags had an individual definition through a schema but were not taxonomically or ontologically linked. That means that programmers working a dataset would lookup the namespace / term of a tag to identify its contents (eg: <dc:title> contains the title string of the works) without the expectation that it would be contained by say a <foaf:Document> - XML tags mean nothing besides pointing to human-readable definitions.
A real world example is the Bibo ontology .n3 definition: the <dcterms:title> terms is copied over from the Dublin Core definition. It may occur (or not) at any time as a property of a node but has no declared relationship to anything. However, the <bibo:shortTitle> term assigns a short title to a <bibo:Document> and won't appear anywhere else. "Dumb" parsers will handle both <bibo:shortTitle> and <dcterms:title> being placed pretty much anywhere while an OWL enabled system will throw an exception if the data is violating the ontological definition.<bibo:shortTitle>. Similarly, a dumb parser would overlook <bibo:annotates> as being a sub-property of <dcterms:relation> and even through it would have a use for the relation: the code does not know what to do with <bibo:annotates>.
Note: To explicitly let a programmer know what to expect, some vocabulary / ontology authors will insist on re-declaring all relevant terms from other vocabularies with <owl:sameAs> statements. An irony is that while not re-using vocabularies in the classical sense, this method explicitly documents all terms in both machine-readable, human-readable and dumb-software-readable formats. This alternative re-use methodology is not based on popularity either (See Schaible et al.[1]) although good documentation and vocabulary popularity helps as "it increases the probability that data can be consumed by applications".
There are a few obstacles to vocabulary re-use:
The domain and ranges of vocabularies and ontologies don't always work well together.
Finding an instance of that term in the appropriate context in the data is a bit more complicated. In the commonly held view, terms appear serendipitously in the (syntactically correct) arrangement that made sense to the data set publisher. So you might get:
<foaf:Person rdf:about="Wilhelm II, German Emperor">
<foaf:name>Wilhelm II, German Emperor</foaf:name>
<foaf:interest>
<rdf:Description rdf:about="dbpedia:hunting">
<rdfs:label>Hunting</rdfs:label>
</rdf:Description>
</foaf:interest>
</foaf:Person>
Which basically means that Kaiser Wilhelm is (was) interested in hunting. This will work with RDF software, but not in an OWL-aware stack that will complain that the range of <foaf:interest> is <foaf:Document>. We can fix that by additionally <rdf:type>'ing the dbpedia url for hunting as a <foaf:Document> and go with the presumption that the term is about hunting and not the act of hunting.
<rdf:Description rdf:about="dbpedia:hunting">
<rdf:type rdf:resource="foaf:Document"/>
<rdfs:label>Hunting</rdfs:label>
</rdf:Description>
Not a big deal in this case, but if the statement had been that he has been <foaf:interest>'ed in dbpedia:German_Empire, it would have made a non-sensical statement that he was interested in a German Empire that was both a foaf:Document and a Place at the same time...
The cost of parsing data increases with the number of vocabularies used.
Not everyone is using Linked Open Data with a Linked Open Data stack. Sometimes, people just grep the data they need from a flat file or xpath their way through an XML dump because that is the fastest way to get the data that they want. For every new name space and/or term set in use within the document, some more exception coding needs to be done. Worse, you need to know what tags to expect somewhere way down into the file because as opposed to SPARQL or other query language you have to know what you are looking for in order to get it.
As an example, we document that Kaiser Wilhelm II knew Edward VII. Neither liked the other very much, but we use "knows" to keep their complicated personal relationship simple. Normally, we'd record that through the built-in Foaf properties but we could have also used the relationship vocabulary to document the web of relationships that link the two.
<foaf:Person rdf:about="Wilhelm II, German Emperor">
<foaf:name>Wilhelm II, German Emperor</foaf:name>
<rdf:Description rdf:about="dbpedia:Edward VII">
<rdfs:label>Edward VII</rdfs:label>
</rdf:Description>
</rel:knowsOf>
<rdf:Description rdf:about="dbpedia:Edward VII">
<rdfs:label>Edward VII</rdfs:label>
</rdf:Description>
</foaf:knows>
</foaf:Person>
<!-- OWL -->
<rdf:Description rdf:about="foaf:knows">
<owl:sameAs rdf:resource="rel:knowsOf"/>
</rdf:Description>
The terms <rel:knowsOf>in the relationship vocabulary and <foaf:knows> in the foaf vocabulary are equivalent, but you have to parse both cases for the same condition if your stack isn't owl enabled and does not understand the <owl:sameAs> triple. Furthermore, if you stated that both were related through an <rel:acquaintanceOf> tag, you will still be in a mess since <rel:acquaintanceOf> implies <foaf:knows> but you need to know about the tag before you parse for it.
Sometimes good practice works against you.
Ontology design rules are there to permit the creation of a consistent systems of logical facts. People approach ontology design in different ways through a sets of design patterns that attempt to avoid inconsistencies, redundancies and ambiguities [2]. Like Third Normal Form (3NF) in classical relational databases, a lot of thought went into these rules but they come at a cost that you may not be willing to bear.
Some of the ontology design patterns include:
- No leaf concepts: Terms that are not exactly matched to the purposes of the ontology, either as sub-classes or super-classes, are discarded from the ontology.
Typical examples of this are Seco and the ARC Marine Ontology:
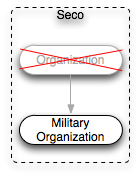

In the Seco world, organizations are military in nature, which is to be expected since it concerns itself with the First World War like Muninn does. However, in line with ontology design guidelines Seco's Military Organizations do not descend from generic Organizations which also means that non-military organizations (like a civil government) aren't supported within this world. You can work around this by adding your own OWL statements that subclass the W3 Organization ontology, but you are then patching the original ontology.
Similarly, if you are trying to record maritime data and you settle on using the Arc Marine Ontology, it is a well engineered ontology to record cruise data. However, you inherit all of their design decisions including the "best practices" ones that may not match your data. All events within ARC are MarineEvent's with no sub-classing of a general event class. That's good practice according to their original requirements but that might not match your data behavior. As an example, if you are recording ship movements, then how do you record non-maritime events that are ancillary to shipping movements like the issuing of manifests or generic weather events? An extra hiccup is that ARC sees a ship as a property to add a string to the cruise. If you happen to record detailed ship-specific properties like tonnage or call-sign, you have to modify the ontology itself so that the domain of the ShipName property does not clash with your data.
- No extraneous concepts: Ontology terms that are not expressed within the data-set, such as a marine population report that has no observation of a type of whale, should be dropped.
The underlying thinking is not to add complexity to an already complex system by only handling the bare essentials or fulfilling the requirement exactly but no further. This can leads to an over-fitting of the ontology to the data-set that it was meant to represent while making it useless for everyone else. This specific best practice is explicitly ignored by some ontology designers in order to make their vocabulary useful to non-OWL enabled systems.
- No redundant concepts: Ontology terms that have the same meaning should be merged. On occasion, this rule is misinterpreted by some designers who fail to differentiate between the thing being modeled and the name of the thing. The result is an ontology that is consistent from a logical perspective but incoherent from a nomenclature perspective. Since reasoners only worry about the logical errors within an ontology, the automated tools will never catch errors that make the vocabulary useless for other users.
An classical example of this is with DBpedia:
<rdf:Description rdf:about="dbpedia:Boiler">
<rdf:label lang="en">Boiler</rdf:label>
<rdf:label lang="fr">Chaudière</rdf:label>
<owl:sameAs rdf:resource="http://fr.dbpedia.org/resource/Chaudière" />
</rdf:Description>
The French word for a boiler is chaudière, which unfortunately also means "a bucket". DBpedia takes a straightforward view of labels in that they aren't disambiguated or annotated per languages as you would using skos-xl. In 90% of cases this isn't a problem since the context of the application handles disambiguation implicitly. However, your own application might have different requirements.
Not everyone see the world the same way.
Persons should be an object that Linked Open Data has figured out by now, but has not. Foaf is likely the most mature ontology used to represent people and pretty much covers most of what you'd want when talking about a person, but it won't handle name changes, multiple names or royal styles. Similar claims are made by CRM-CIDOC's crm:E21.Person, dbpedia.org Person, FRBR Person, BibFrame Person, schema.org Person and I am likely missing a few (See Brown and Simpson [3]). People are pretty much the single most important thing in modeling and yet we have a long list of definitions and re-definitions of classes for defining a person. And don't get me started about handling fictitious people.
The other tradeoff in that people tend to optimize their work for their problems: Foaf was meant to support people in an internet context when it was written, this is obvious in its support for online accounts, projects worked on and tipjars. schema.org is meant to streamline the process that tells search engines what your webpage is about. It does a pretty good job for day-to-day use, such as recording the location of a curry place you like. But it won't record its last address before it moved or the name of its previous owner. Similarly, Muninn worries about the First World War and the ontologies tend to be highly tuned to the problems of that era.
Another example of differing views on the world is the differing ways in which Seco, DBpedia and Muninn see Corps organizations in an army. An army corps can either be a formation of troops that is part of an army or a unit with a specialized purpose. Because DBpedia is derived from the Wikipedia that explains both concepts, the dbpedia Corps term is not disambiguated and hence matched Muninn's Corps disambiguation term. Seco's term for a Corps is under-specified and used when the name of the unit has 'Corps' listed in it.
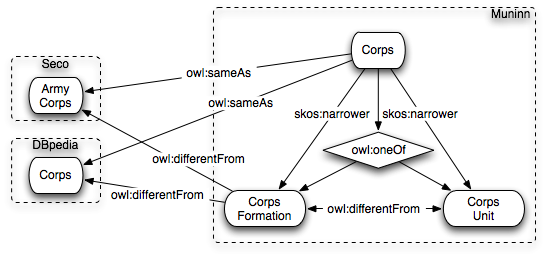
Hence if your dataset would be about the Royal Pioneer Corps or the Machine Gun Corps, using either Seco or DBPedia's terms would not be outright wrong, but it would be under specified. You likely would want to use Muninn's CorpsUnit term to specify the unique mission assigned to Pioneer troops.
Different applications need different levels of complexity
Where did Nelson pass away?
We know that Admiral Nelson was shot by a marksman at the Battle of Trafalgar. He was brought below deck of his flagship HMS Victory. Dramatically different approaches to recording this events is possible that are completely incompatible with each other while being completely reasonable on an individual basis. A very simple approach to modeling this event using DBpedia's placeOfDeath property.
<DBpeda:Horatio Nelson> <dbpedia-owl:deathPlace> <DBpedia.org:HMS Victory> .
Take for example Nelson's death at Trafalgar. Very complex modeling can be done with some ontologies like CRM-CIDOC [4] which require large amounts of triples and a very deep understanding of the ontology. If that level of detail isn't right for you, another solution might be to build a location piecemeal:
Nelson actually died of his wounds in the cockpit of the orlop deck of the HMS Victory. We don't have the full trajectory or position of the ship at the time, but its not necessary. All we really need is to define the place and to link it to the ship.
<foaf:Person rdf:about="">
<foaf:name>Horatio Nelson, 1st Viscount Nelson</foaf:name>
<rdf:Description rdf:about="NelsonDeathLocation">
<rdfs:label>Cockpit, Orlop Deck, HMS Victory</rdfs:label>
<rdf:type rdf:resource="Orlop Deck"/>
<rdf:type rdf:resource="Cockpit"/>
<rdf:type rdf:resource="Feature"/>
<dc:partOf rdf:resource="HMS Victory"/>
<ogc:sfWithin rdf:resource="Cape Trafalgar"/>
</rdf:Description>
</dbpedia-owl:deathPlace>
</foaf:Person>
Depending on the complexity of the data and the application that is being worked on, different vocabulary choices will be made.
Conclusion
Vocabulary re-use isn't the silver bullet that it is sometimes advertised for the simple reason that unless the vocabulary is a perfect match to the type of data you are publishing it is likely missing something that you need. There is a lot of great engineering done in vocabularies and the right mix of re-use, addition, modification and roll-your-own will help you create a great data-set.
1. geo:Point' is meant to handle a single point in WGS84 (GPS) projection while the GeoSPARQL asWKT( is a container for GML strings that can define projections different from WGS84. Most implementation of GeoSPARQL I've seen so far assume a default of WGS84 for a GML snippet like POINT (x y), but that is not set in stone and someone might get very bizarre results depending on the engine they are using.
2. rel:knows_Of was changed from a subproperty of foaf:knows to work around the reciprocity problem. Relationship accepts that a person might know about someone without the reverse being true. Foaf does not.
References
- , “Survey on common strategies of vocabulary reuse in linked open data modeling”, in The Semantic Web: Trends and Challenges, Springer, 2014, pp. 457–472.
- , “Problems impacting the quality of automatically built ontologies”, Proceedings of Knowledge Engineering and Software Engineering, vol. 949, 2012.
- , “The curious identity of Michael Field and its implications for humanities research with the semantic web”, in Big Data, 2013 IEEE International Conference on, 2013.
- , “CRMgeo: Linking the CIDOC CRM to GeoSPARQL through a Spatiotemporal Refinement”, 2013.
English