It's been a year since LODLAM 2020 took place at The Getty in LA, right before the Covid-19 pandemic hit. It seemed that my bags were barely unpacked that things went dramatically wrong as venues, institutions and cities began shutting down. Rush hour downtown Toronto was an odd spectacle of office workers awkwardly taking their computer monitors with them on commuter trains, ready for an extended period away from work. All of us ended up in one of two categories: those forcibly (and frustratingly) idled and those run ragged trying to keep the lights on. 2020 was for many a "lost year" of extremes where we did our best not to drop too many balls along the way.
A year late, here is my LODLAM 2020 recap:
 Science Stories was the winner of the LODLAM challenge, featuring a biography of Grace Hopper and others. The demo website seems to be having hiccups but the challenge video is still up here. The list of entries is contained here and consisted of Biography Sampo, Center for Integrated Studies, The Israel Museum, American Art Collaborative, ExpLOD, LD4P Questioning Authority and Golden Agents.
Science Stories was the winner of the LODLAM challenge, featuring a biography of Grace Hopper and others. The demo website seems to be having hiccups but the challenge video is still up here. The list of entries is contained here and consisted of Biography Sampo, Center for Integrated Studies, The Israel Museum, American Art Collaborative, ExpLOD, LD4P Questioning Authority and Golden Agents.
Sessions included "Then What? User Interfaces for LOD", "LOD Education and Training", "How to get colleagues excited / Uncertainties in LOD", "Software Implementation, MetaPhacs, BIBFRAME", "Modeling Exhibitions / Machine Readable Profiles / Pragmatic Approaches", "Wikidata Best Practices", as well as a less-than-curated list of links.
The takeaway, 10 years after this unconference started, is that LODLAM is still a mixed bag: some people are at the bleeding edge while others are not quite there yet. There has been criticism that LODLAM has become more of a destination unconference rather than one where things get done. There is likely some truth to this, but formalizing the unconference further will likely pigeonhole it into a topic silo preventing a multidisciplinary approach.
Cultural Institutions Under Lockdown
A certainty is the value of properly curated and structured data. Streaming services like Amazon Prime Video are booming with the lockdowns and are taking advantage of resources such as IMDB to create very complex and effective recommendation systems. I'm highlighting Amazon Prime's Xray system in particular for its ability to repurpose metadata. Depending on the show and episode, pop-ups for additional content such as shooting locations, show trivia and supporting actor movie recommendations appear on the screen. One feature that I found especially intriguing was the use of some clever computing to link scene background music to band and title data. That alone has probably done more for smaller indie bands in the past year than anything else. Surprisingly, the technology and data to do this has been available for years.
On the museum side, it will be interesting to see what lockdown measures will have forced cultural institutions to consider. If your primary attraction can no longer be accessed, how can its data be used to support its educational mission? Putting on my military history hat for a second, I want to point out the work done by the staff of the Battleship New Jersey Museum who have been funding their museum by having their curator create video after video of inaccessible parts of the ship to keep the museum funded. It isn't linked open data, but it is a great example of simple technologies giving access to ship locations, such as the electrical trunks and shaft alley, that will never be accessible to the public for safety reasons.
Document, Document, Document!
 Back to LODLAM itself: I wanted to follow up to my comments during the dork shorts (and while jogging up and down the auditorium stairs with a microphone) about documentation and communication. The primary benefit of linked open data is the ability to communicate context and knowledge that would otherwise be implicit and thus lost. However, that requires that you understand your own data and, very frankly, most people don't.
Back to LODLAM itself: I wanted to follow up to my comments during the dork shorts (and while jogging up and down the auditorium stairs with a microphone) about documentation and communication. The primary benefit of linked open data is the ability to communicate context and knowledge that would otherwise be implicit and thus lost. However, that requires that you understand your own data and, very frankly, most people don't.
The reasons for this can be blind adherence to standards, a focus on the artifacts over the data about the artifacts and a view of data as "an IT thing" - as one participant put it: "You programmers, you're never any good at documenting things". (Maybe it's a bit much to expect them to do theirs jobs, be an expert on Sumerian art and guess correctly at what wasn't written down?) Bad communication is not only a LAM issue: computing is collectively making a experiment with "Documentation by Blog Post" instead of official documentation that I personally find horrifying and doomed to failure. On the Academic side, editors have been working on supporting "Data Papers" through publishers and data archiving through archiv and zenodo. These are all good ideas, but remember that if you can't understand your own data or you don't communicate its significance using LOD principles, the patrons consuming your data aren't likely to do so either.
Looking forward to 2022!
In closing, I'd like to plagiarize the advice given by Charlie Clarke to the subsequent organizing committee to SIGIR 2003 that took place during the first SARS outbreak: "Don't invent a new disease!". Fingers crossed that things will return to normal in a year. Rumours of a LODLAM 2022, possibly in Europe, are still floating around the ether...
Best of health from the LODLAM 2020 committee: @joanbcobb @adrianstevenson @ewg118 @muninn_project @ccthompson @marciazeng






 The
The 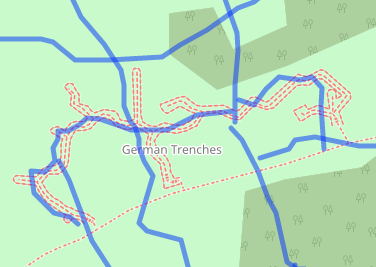 A survey section during the war would be expected to triangulate a feature within 20 yards while out in the field. In actuality areas of high activity were well surveyed and the accuracy of a trench map is often within 5 yards for important features. Since we used hand tracing to extract the trenches some inaccuracy is to be expected. One can do much better by creating a line finding algorithm that traces the trench based on colour separation and that will be the topic of future work. The figure to the right is an
A survey section during the war would be expected to triangulate a feature within 20 yards while out in the field. In actuality areas of high activity were well surveyed and the accuracy of a trench map is often within 5 yards for important features. Since we used hand tracing to extract the trenches some inaccuracy is to be expected. One can do much better by creating a line finding algorithm that traces the trench based on colour separation and that will be the topic of future work. The figure to the right is an  When the Muninn Project started several years ago, it was a wild idea that started at the paper napkin stage and that slowly evolved into one of the more complex projects in the
When the Muninn Project started several years ago, it was a wild idea that started at the paper napkin stage and that slowly evolved into one of the more complex projects in the  It was a busy July in
It was a busy July in